

Über 39 kiloDalton
Mission Impf-possible



“39 kDa ist wie Mission Impossible (nur ohne Tom Cruise). 22 N-Glykosylierungsstellen, "mehrere" 0-Stellen, OK. Die durchschnittliche Glykosylierungsrate beträgt 5 %. Top-Glykane mw ist 430D. Wenn es wirklich stark glykosyliert ist, haben wir es mit 4 kDa zu tun. Das theoretisch mögliche Maximum wäre etwa 13 kDa.”

Vor einiger Zeit haben wir in einem Thread mit Jikky darüber berichtet, wie in einer Studie das Molekulargewicht eines tatsächlich impfproduzierten Spike gemessen wurde. Wir berechneten Spike und das Protein war wesentlich höher als erwartet, als ob die Translation weiterlief und mehr Aminosäuren zusammengebaut wurden.
Natürlich sind alle Threads von Jikky verschwunden. Wir haben also in einer echten angeregten Diskussion eine Antwort gesucht, wie man 39kDA mehr Molekulargewicht erklären kann, als man bei Spikeproteinen erwarten würde.
Es geht um folgende Studie, welche mit exotischster Schätzmethodik anstelle einer simplen Massenspektroskopie 39kDa durch Glykolisation erklären wollte:
https://medrxiv.org/content/10.1101/2022.03.01.22271618v1

Doch wie unschwer zu erkennen ist, waren auch noch 5 Tage später 3 Bänder zu sehen, was schon mal eindeutig gegen diese These spricht, da es stabile Proteine zu sein scheinen.

Woran erkennst du also betrügerische Studien, die Zeilen hinzufügen, die keinen Sinn ergeben?


“200kDa (60kDa für Glykane) sind nicht zu fassen. Diese Zeile wurde ohne jegliche Berechnung in das Papier geworfen. Selbst wenn sie wahr wäre (spielen wir mal "wenn"), würden 39 kDa eine Glykolyseeffizienz von 60 % ergeben, was nur möglich wäre, wenn das endoplasmatische Retikulum in irgendeiner Hinsicht magisch wäre.”
Moment, Moment. Das klären wir gleich:
Readthrough

Was da recht kompliziert klingt, heißt nichts weiter, als dass die Stopcodons ignoriert und einfach weiter translatiert wurde:

Das in rot markierte sind die stop Codons. Und hier der Knüller. Wir haben unsere 39 kDa dann doch noch gefunden. Oder vielmehr hat es der Herr Biochimiste, dem ein spezieller Dank gilt, ausgerechnet:
“Wenn Stop-Codons durchgelesen werden, fügt es 25,91 kDa ohne das polyA hinzu, und das polyA fügt weitere 4,62 kD hinzu. Insgesamt kommen also 30,53 kD hinzu. Die Glykosylierung könnte zwischen 4 und 13 kD hinzufügen. 39 - 30,53 = 8,46. Das passt völlig. Wir haben es hier mit einem Protein zu tun, bei dem 3'UTR+polyA übersetzt werden.”

Einschub (18.07.2022)
Vielen lieben dank, Herr Dr. Zimmer, für diesen brutalen und erschreckenden Hinweis. ♥
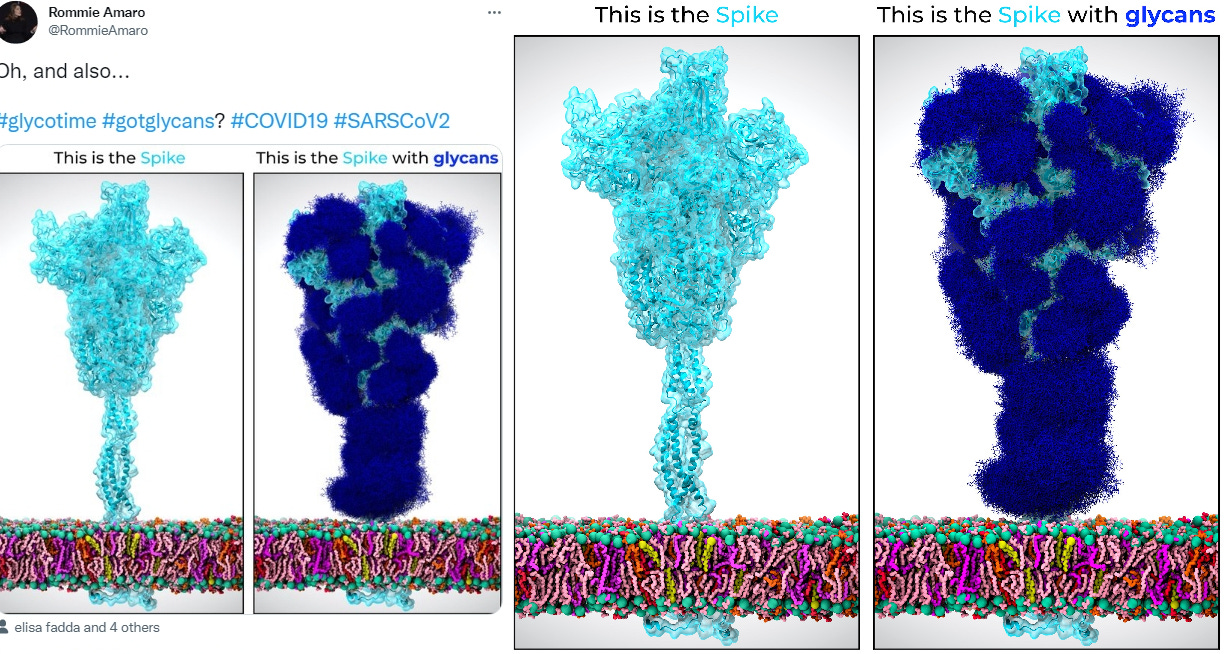


“Bei stark glykosilierten Proteinen gibt es zwei Effekte, die sich auf das Laufverhalten in der SDS-PAGE auswirken: zum einen natürlich der Massegewinn durch die Zuckerreste. Aber vor allem kann das Protein nicht mehr gut mit SDS beladen werden. Und das haut jegliche Vergleichbarkeit mit anderen Größenmarkern völlig kaputt. Wesentlich bei der SDS-Page ist die SDS Beladung, wodurch die Proteinladung und der Isoelektrische Punkt der Proteine vollständig negiert werden. Dadurch ist nur noch die Proteingröße für das Laufverhalten ausschlaggebend.”
Dieses Hübsche was auch immer könnte also schon Morgen Ihnen gehören:

Wovon auch immer wir hier also reden, ist kein verdammtes Spikeprotein mehr, sondern ein nettes Human-Virus-was-auch-immer-Protein.
Wird das für alle Translationen gelten? Nein. Natürlich nicht. Aber bei der Masse an Spikes, die durch die klebrige, mit m1Pseudouridin (m1Ψ) substituierten Codes (jedes U = m1Ψ) produziert werden, reicht es locker aus, um höllischen Schaden anzurichten.
Schauen wir uns noch kurz die Leseregeln zu m1Ψ an:

“Unabhängig von der Sequenz der RNA oder der Art des in der Reaktion verwendeten Uridinanalogons wurde beobachtet, dass die Basensubstitution für die überwiegenden Fehler verantwortlich war, die zwischen 73 % und 96 % der Gesamtfehler lagen (Tabelle S2).”
(…)
”Die rA→rU/dT→dA-Fehlerraten in ψ-modifizierten RNAs waren etwa neun- bis 12-mal höher als bei unmodifizierten RNAs. Die rA→rU/dT→dA-Substitution war auch bei m1ψ-modifizierten RNAs offensichtlich (bis zu dreimal höher als bei unmodifizierten RNAs), wurde aber im Vergleich zum ψ-modifizierten Gegenstück als geringer eingestuft.”
Hört sich das nicht nett an? Wir haben also eine Gesamtfehlerquote bei der Translation, die jenseits von Gut und Böse ist.
Und wer sich gerade fragt, was mit dem poly-A-tail geschieht, der möge sich einfach mal diese Studie auf der Zunge zergehen lassen:
A wird prinzipiell in K übersetzt (Adenylat zu Lysin)



“Diese Ergebnisse deuten darauf hin, dass dieser Prozess von entscheidender Bedeutung sein kann, wenn während der Entwicklung oder der Tumorentstehung Veränderungen an der Polyadenylierungsstelle auftreten oder wenn die Terminierung/Recycling der Translation gestört ist.” (Aus dem Abstrakt)
“Wir gehen davon aus, dass die Rolle von Dom34 unter Bedingungen, unter denen die Poly(A)-Translation weiter induziert wird, noch wichtiger wird. So wurde zum Beispiel vorgeschlagen, dass neuronale Aktivierung und einige Krebsarten vorzeitige Polyadenylierungsereignisse hochregulieren (Berg et al. 2012; Tian und Manley 2013).”
Klingt also direkt nach der nächsten Erfolgsgeschichte, denkt ihr nicht auch?
Addendum 2022-07-22
Doi: 10.1016/j.comptc.2021.113414



Noch ein kleiner Funfact zu m1Ψ:
https://de.wikipedia.org/wiki/Stopcodon

”Als Stopcodon oder Terminationscodon, auch Nonsense-Codon, wird in der Genetik ein Codon der Ribonukleinsäure (RNA) bezeichnet, für das keine zugehörige tRNA (transfer-RNA) vorliegt und das daher das Ende einer Sequenz von Nukleotiden darstellt, die an Ribosomen in die Sequenz von Aminosäuren eines Polypeptids übersetzt werden können.
Ein Stopcodon bestimmt damit das Ende eines Leserahmens, der die Biosynthese eines Proteins erlaubt, und ist somit notwendige Bedingung für einen codierenden Nukleinsäureabschnitt. Das Basentriplett eines Stopcodons auf einer mRNA (messenger-RNA) führt bei der Proteinbiosynthese in einer Zelle zum Abbruch der Translation und markiert so – ähnlich dem Punkt am Ende einer Wortfolge bei einem Satz – das Ende der für ein Protein codierenden Nukleotidsequenz und damit dessen Satz an zu verbindenden Aminosäuren. Das Gegenstück zum Stopcodon ist das Startcodon zu Anfang dieser Nukleotidsequenz, wo die Translation beginnt.”
Heißt also, dass das Stopcodon ebenfalls in wie ein “normales Codon” gelesen und translatiert werden könnte.
http://frontiersin.org/articles/10.3389/fimmu.2022.941009/full


Kann mir irgendwer verraten, was Bakterienähnliche Codes in einem Virusspike zu suchen hätten?!
https://www.researchsquare.com/article/rs-1844677/v1

S1-Protein und mutiertes Protein - wie von uns vorhergesagt - in Monozyten 90 Tage nach der Impfung gesehen.
Und das dürften dann die 39 kDa sein. Viel Erfolg allen, die immer noch nicht zuhören möchten. (Es würde mich nicht überraschen, wenn dieses Paper beerdigt wird. Euch?)
Liebe Grüße und ein weiteres fettes Narf, euer Genervter Bürger.